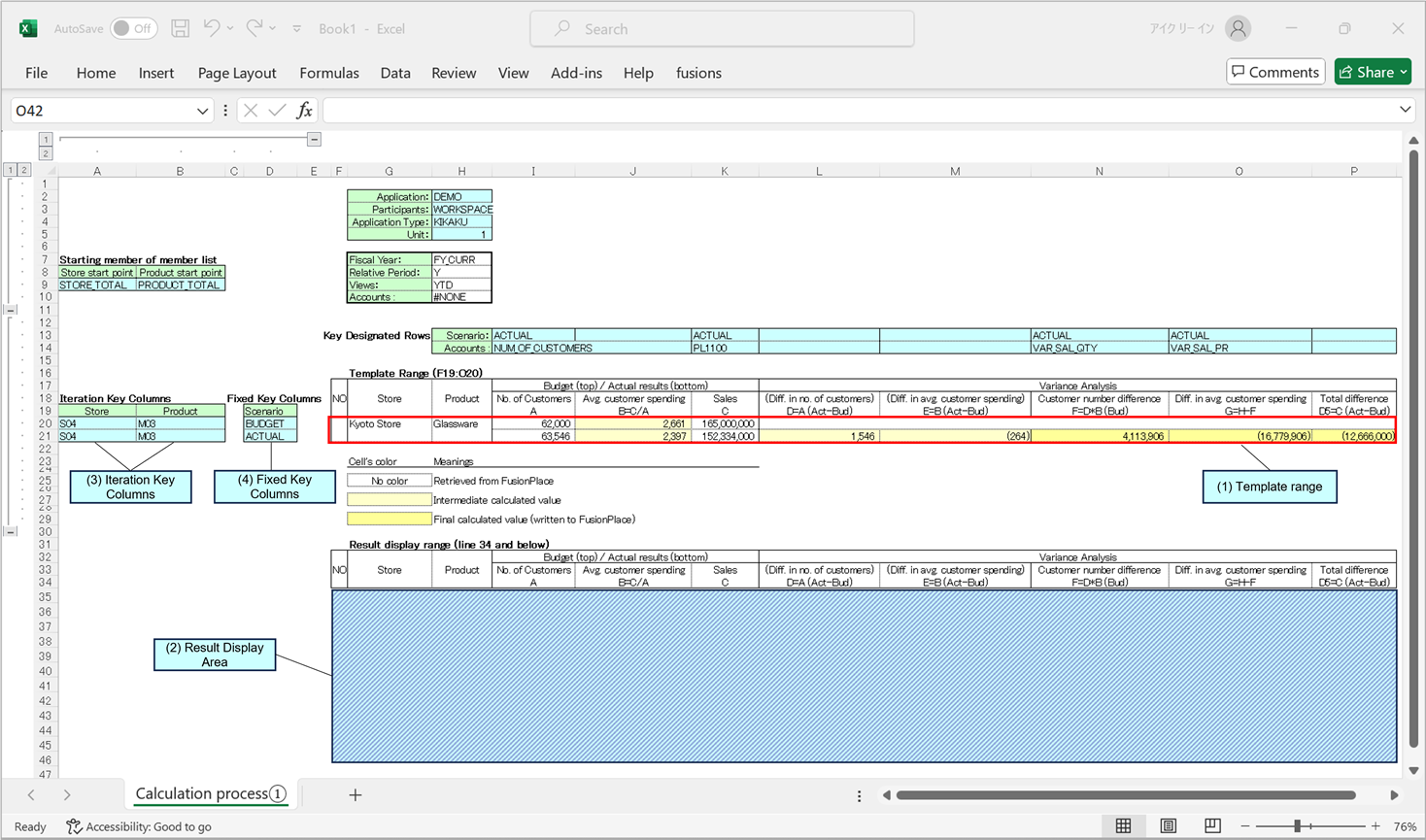
Layout of Template Processing Target Sheet
This manual is in pilot operation.
|
Template processing is a mechanism for executing the same process for multiple members (or combinations of members). With template processing, the following processes can be easily achieved:
-
Creating reports with variable row numbers using Excel-Link (alternatively, consider using Forms).
-
Performing complex calculations based on fusion_place data and reflecting the processing results in the ledger.
-
Creating reports comparing data values from multiple ledger editions (this cannot be done with forms).
The layout of an Excel sheet applying template processing functionality is explained using the sample diagram below:
To utilize template processing, a "Template Range [as shown in Figure (1)]" must be provided on the Excel sheet. The template range is a rectangular cell range that can include one or more linked regions to retrieve data from the fusion_place application. The calculation model composed of formulas in each cell within the template range is executed for multiple member combinations specified in "Iteration Conditions".
The results of the calculation process performed in the template range can be written to the fusion_place ledger or output to the "Result Display Range [as shown in Figure (2)]" set up on the same sheet as the template range.
Below, we explain the concepts necessary for setting up template processing.
Template Range
The template range defines the content of the calculation process to be repeatedly executed within a rectangular cell range. Within the same range, you can include one or more linked regions to retrieve data from the fusion_place application. Additionally, using Excel formulas, you can perform calculations based on these data and values from other cells. The results of the calculations can also be written to the fusion_place ledger through the linked regions for reflection.
Only one template range can be provided per sheet.
Template ranges can be specified in the " Sheet Processing Instructions".
Iteration Conditions
"Iteration Conditions" specify the sequence of members (or combinations) to which the calculation model set in the template range is applied. Although not shown in the diagram above, iteration conditions can be specified in the " Sheet Processing Instructions".
For the simplest single iteration condition, specify a specific member list for a specific dimension and also specify the "Iteration Key Column [as shown in Figure (3)]". Then, the labels of the members contained in that list are sequentially assigned to the iteration key column next to the template range, and data retrieval and calculation are performed within the template range. The results can be written to the result display area or reflected in fusion_place (how to handle calculation results depends on the specifications regarding template processing).
Similar iteration processing can also be performed for multiple lists of members of different dimensions (multiple iteration processing). For example, suppose dimension A’s member list AL1 is associated with column A, containing members a1, a2, and a3. Additionally, suppose dimension B’s member list BL1 is associated with column B, containing members b1 and b2. In this case, a maximum of six combinations of members (combinations of a1, a2, a3, and b1, b2) become processing targets. In practice, the processing targets for member combinations are determined according to the specification of the "Show all combinations cell" in the " Sheet Processing Instructions" under "Iteration Conditions" as follows:
| < Condition 1 > If "Show all combinations cell" is… |
< Condition 2 > If the value of "Show all combinations cell" is… |
< Member combinations to be processed > |
|---|---|---|
Not specified |
--- |
Each combination in the set is evaluated for the presence or absence of data. As a result, member combinations with existing data are selected for processing. |
Specified |
If the logical value is "TRUE" or is interpreted as true in Excel calculations |
All combinations of members in the member list are processed. |
(Other than the above) |
In principle, the same as when the "Show all combinations cell" is not specified. However, if no control regions are specified, it does not result in an error, and all combinations of members in the member list are processed. |
In the example above, columns A and B are iteration key columns, with column A associated with the store dimension and column B associated with the product department dimension.
In specifying iteration conditions, the following conditions are specified for each dimension to be iterated:
| Item | Required | Specification |
|---|---|---|
Dimension |
✓ |
Dimension containing the member list to be iterated. |
Column |
✓ |
Column for setting the iteration key corresponding to the specified dimension. |
Member List |
✓ |
Definition of the member list specifying the members to be iterated. |
Starting Member Cell |
― |
Required only if the member list requires a "perspective member". It serves as the starting point for creating the actual member list in conjunction with the member list definition. |
To specify multiple iteration conditions, specify the iteration conditions for multiple dimensions as above. Iteration conditions have an order, where the iteration condition listed first specifies the outermost (larger) iteration, followed by sequentially specifying inner (smaller) iterations.
Result Area
In the result area, the calculation results in the template range are written out in order for each processed member (combination) from the top down. Like iteration conditions, the result area can also be specified in the "Sheet Processing Instructions".
The result display is not mandatory. If you retrieve data from fusion_place, perform some calculations, and reflect the processing results back to fusion_place, you may not necessarily need to display the processing results one by one (you can create validation reports in fusion_place forms). In that case, if you deliberately do not specify the result display area, the results will not be displayed, but the processing itself will still be executed.
The order of writing to the result display area follows the order of members within the member list specified in the iteration conditions. Along with writing the values of each cell in the template range, you can additionally copy the formulas, formats, and input rules of the template range.
In the result display area, in addition to data values, you can specify to write out the following attributes of each cell in the template range:
-
Formulas
-
Formats
-
Input rules
The result display area must be provided on the same sheet as the template range, below the template range. When setting up template processing, only the first row of the result display area needs to be specified. The start column and end column of the result display area are equal to the start column and end column of the template range, and the last row of the result display area is the last row of the sheet. In other words, the range below the template range from the first row of the result display area onward may all be used for result display. Do not use it for other purposes.
The number of rows in the result display area is limited by the maximum number of rows in the Excel sheet. If the number of rows exceeds the maximum number of rows in the sheet, the results exceeding the maximum number of rows will not be displayed, but the processing itself has been performed. That is, even if the rows are not displayed, the processing results are reflected in fusion_place.
After the data retrieval process, the following "names" including the result display area are automatically set. The applicable scope for all names is the target sheet:
- Print_Area
-
The printable area. This is set to the result display area.
- _FP_Database
-
The cell range including one row above the result display area is set. When creating a pivot table based on the result display area, etc., it is convenient to specify the target range not by address but by this name, as the target range of the pivot table is automatically changed each time data is retrieved.
Types of Row Key Columns
Within the template range, it’s possible to provide one or more linked regions. Each row key designated column of each linked region is classified into one of the following three types from the perspective of template processing:
1. Iteration Key Columns [Refer to Figure 3]
These columns do not overlap with the template range and are designated as the target columns in the "iteration conditions" mentioned above. In template processing, for each row within the template range, the cell at the intersection of that row and the iteration key column is assigned the label of one member contained in a specific dimension’s member list. This process is repeated for each member in the member list.
There can be multiple iteration key columns within a single linked region. In this case, each iteration key column is associated with a different dimension’s member list. Thus, template processing allows not only iterating over a single dimension’s member sequence but also repeating the process for each combination of members taken from multiple dimensions.
If multiple rows are included in the template range, the same iteration key value is applied to all rows.
2. Fixed Key Columns [Refer to Figure 4]
These columns do not overlap with the template range and are not designated as the target columns in the "iteration conditions." When template processing begins, the template range is cleared; however, for fixed key columns, the value at the immediate subsequent point in time is used as the key throughout the entire process.
If multiple rows are included in the template range, a different fixed key value can be applied to each row.
3. Calculated Key Columns [No corresponding example in the figure]
These are row key columns that overlap with the template range. The key values of calculated key columns are recalculated each time data is retrieved, based on the retrieved values, etc. Subsequently, data retrieval is performed based on the recalculated keys. This process continues until the retrieved data value stops changing or until the repetition limit (10 times) is exceeded. By using calculated key columns, it’s possible to further retrieve or reflect data from fusion_place using data retrieved from fusion_place as keys.
By using calculated key columns, for example, currency conversion processes can be easily implemented. By taking each member of the company dimension, retrieving the value of its "currency" property (i.e., currency code), using that currency code as a key to retrieve exchange rates from the exchange rate ledger, and multiplying it by the company-specific account amount in local currency obtained from another ledger, the converted company-specific account amount can be calculated (it can also be written to the ledger). If multiple rows are included in the template range, a different calculated key value can be applied to each row.
Control Region and Data Existence Determination
Among the linked regions included in the template range, the linked region used to determine the existence of data is called the "control region". The control region must meet the following conditions:
-
The "Region Type" is "Data Region."
-
It is the target of data retrieval processing (i.e., the "Processing Category" is anything other than "Reflection Only").
-
All iteration key columns are designated as the row key columns of that linked region.
-
The calculated key column is not included in the row key designated columns of that linked region.
-
The setting of "Do not involve in data existence judgment in template processing" is OFF in that linked region’s configuration.
A region that satisfies these five conditions is called a "control region." There must be at least one control region within the template range (multiple regions are also acceptable).
When processing all iteration keys (combinations), there is a possibility of a vast number of combinations. Therefore, in template processing, except for when processing all iteration keys (combinations) according to the specified by the "Show all combinations cell", the existence of data is first determined for each iteration key (combination). Then, data retrieval and reflection processing are performed only for the combinations where data exists (see "explanation of iteration conditions"). For the determination, data retrieval conditions related to the control region are used. If there are multiple control regions, each iteration key (combination) is processed only if data is available in any of the control regions. In the judgment, zero values are treated as no data.